Author: David Lo, Luis Argueso and Nicholas Janiga, ASA | Published: 8/1/2019
Researchers and companies have long been gathering data to gain new insights into health and illnesses. With the significant increase in use of electronic health records, patient health data has become more accessible than ever before. According to EMC Digital Universe, the amount of healthcare data is expected to grow by 48 percent per year through 2020, outpacing the growth in data from other industry sectors.
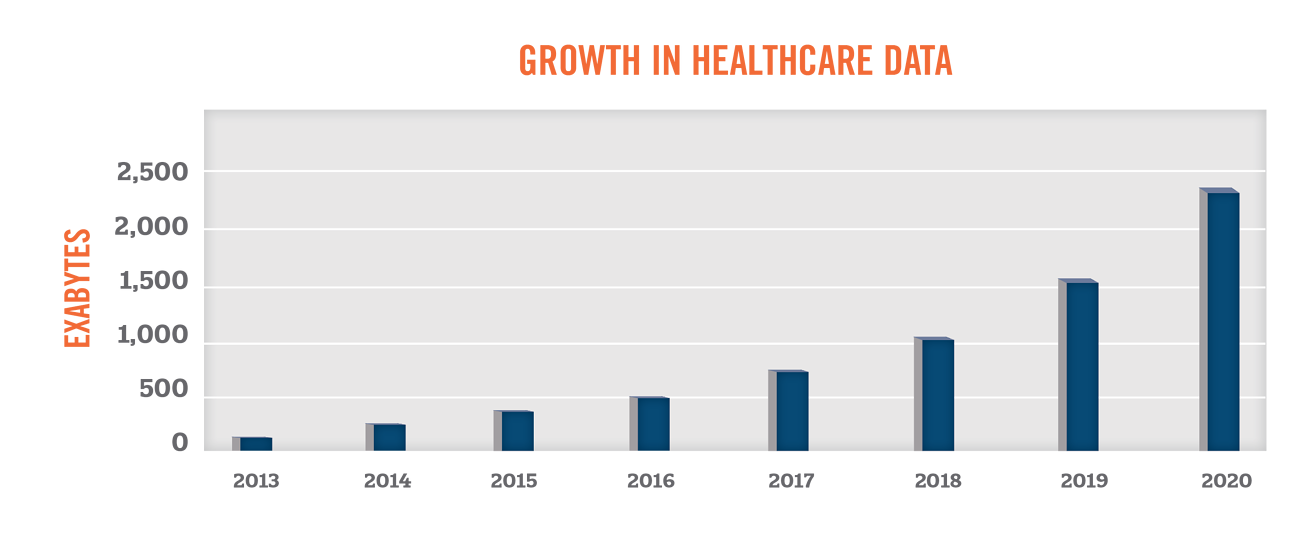
With the growth in the volume, scope, and quality of health data, industry participants have been seeking new ways to leverage such information to further the “triple aims” of improving the experience of care, improving the health of populations, and reducing costs.[1] This paper serves as a primer in understanding the growing uses of health data, compliance challenges associated with health data, and the value of health data to market participants in the healthcare industry.
Health data is defined as information related to health conditions, reproductive outcomes, causes of death, and quality of life.[2] The scope of health data continues to expand as new ways of generating and collecting health data become available. Health data now includes personal wellness data from wearable devices (e.g., smart watches or fitness trackers). The data collected by these devices continues to improve as the sensors become more sophisticated (i.e., the inclusion of ECGs in smart watches). Companies, such as 23andMe, charge consumers to learn about their health or origins using genetic data, while aggregating the DNA data for further research. Large consumer technology companies are also entering the healthcare market. For example, Apple’s development of the Apple Watch includes a Health App which allows users to transfer clinical data to their iPhones (which users can choose to share with Apple). Apple has also developed a platform called ResearchKit to provide a software framework to medical researchers to help gather more robust and meaningful health data.
Key users of health data include patients, payors, governments, medical device and pharmaceutical companies, and healthcare providers. Furthermore, large technology and artificial intelligence start-up companies are also developing new services and products that require the use of patient data. While patient data is already being traded at an aggregated and anonymized level, there are still many concerns with patient privacy. The Health Insurance Portability and Accountability Act of 1996 (“HIPAA”) protects the privacy of patients and sets forth guidelines on how this private health information can be shared. Though the privacy of a patient must be protected, the legal right of a business to sell health information of patients has been upheld by the Supreme Court of the United States. [3]
Privacy
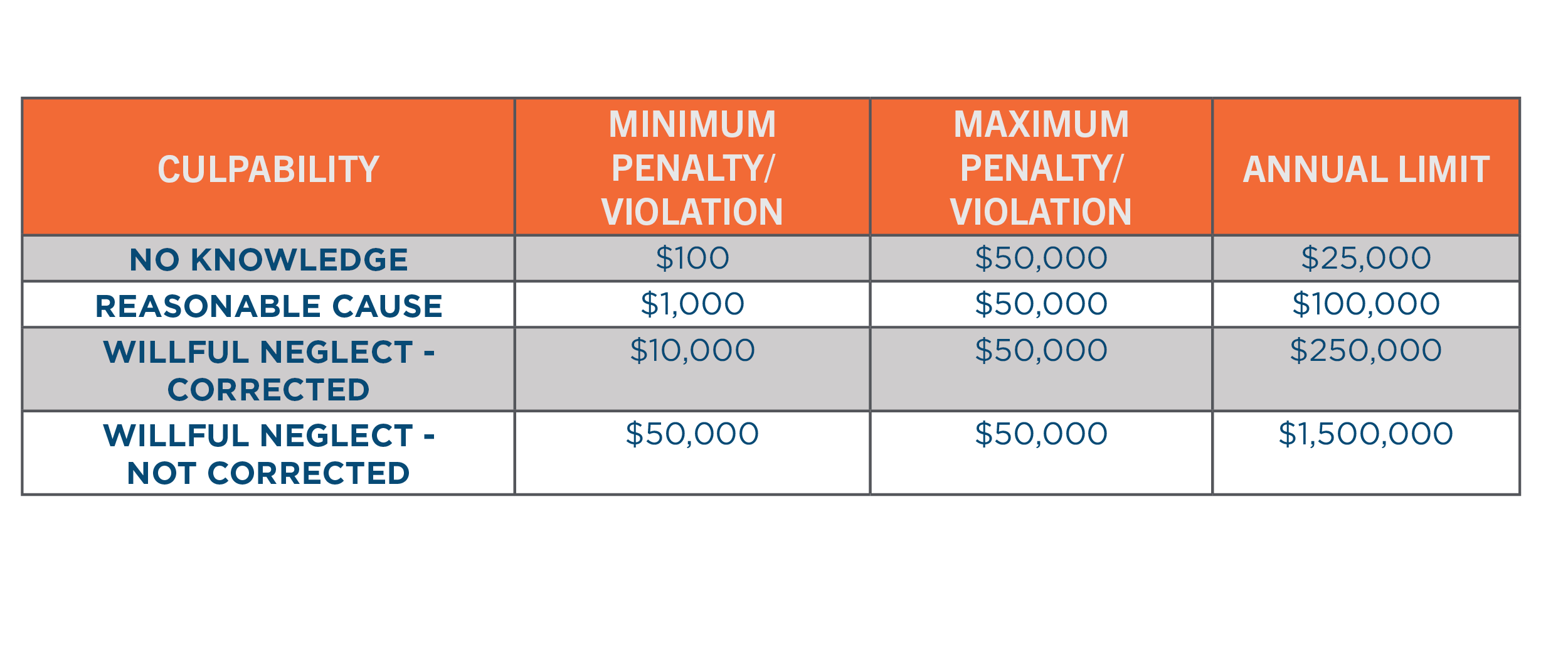
In the United States, the HIPAA Privacy Rule requires appropriate safeguards to protect the privacy of personal health information. The failure of to comply with HIPAA can result in fines ranging from $100 to $50,000 per violation or per record. As of April 30, 2019, the Department of Health and Human Services (HHS) revised the possible penalties based on the level of culpability, outlined in the following table[4]. In 2018, over $28 million of fines were paid for HIPAA violations.[5]
The HIPAA Privacy rule provides two standards for the disclosure of protected health information without seeking patient authorization:
- Safe Harbor Method
- Expert Determination Method
The Safe Harbor Method is a precise standard for the de-identification of personal health information when disclosed for secondary purposes. It requires the removal of 18 identifiers from a dataset. While this is the safest method of de-identifying data, the exclusion of these identifiers renders the data less useful. The 18 identifiers include the following:
- Names;
- All geographical subdivisions smaller than a State, including street address, city, county, precinct, zip code, and their equivalent geocodes, except for the initial three digits of a zip code, if according to the current publicly available data from the Bureau of the Census: (1) The geographic unit formed by combining all zip codes with the same three initial digits contains more than 20,000 people; and (2) The initial three digits of a zip code for all such geographic units containing 20,000 or fewer people is changed to 000.
- All elements of dates (except year) for dates directly related to an individual, including birth date, admission date, discharge date, date of death; and all ages over 89 and all elements of dates (including year) indicative of such age, except that such ages and elements may be aggregated into a single category of age 90 or older;
- Phone numbers;
- Fax numbers;
- Electronic mail addresses;
- Social Security numbers;
- Medical record numbers;
- Health plan beneficiary numbers;
- Account numbers;
- Certificate/license numbers;
- Vehicle identifiers and serial numbers, including license plate numbers;
- Device identifiers and serial numbers;
- Web Universal Resource Locators (URLs);
- Internet Protocol (IP) address numbers;
- Biometric identifiers, including finger and voice prints;
- Full face photographic images and any comparable images; and
- Any other unique identifying number, characteristic, or code (note this does not mean the unique code assigned by the investigator to code the data).
The Expert Determination Method requires an expert with appropriate knowledge of and experience with generally accepted statistical and scientific principles and methods for rendering information not individually identifiable to certify that there is a “very small” risk that the information could be used by the recipient to identify the individual who is the subject of the information.[6] Recent studies have demonstrated that the re-identification of protected health information may be done alone or in combination with other reasonably available information[7] or with the use of artificial intelligence.
[8]Based on the methodology used to de-identify health data, the usability and the “power” of data will have a large determinant on the potential use and consequently the value of the health data.
Value of Data
As the sources, users and uses of patient health data continues to broaden, the purchase and sale of data will increase. In order to value patient data, it is important to understand the type of data being sold or purchased. As described previously, data that has been de-identified under the Safe Harbor Method (e.g., claims data) will be much less useful than longitudinal data that has been de-identified using statistical methods (e.g., clinical data from an EHR or clinical trial results).
Another challenge of valuing de-identified health data is the wide variety of uses of data. HAI has observed that academic researchers are sometimes able to obtain health data at a discount or for free as they are using the data for non-commercial purposes that provides a benefit to the public. On the other end of the spectrum, companies may be able to use the data to develop non-existing products or treatments, for which the expected value is unpredictable. Given these factors, the Market Approach and Cost Approach are typically most appropriate when valuing data sets.
The application of the Market Approach requires the identification of comparable transactions where similar types of data sets have been bought and sold. Then a qualitative assessment of the subject data relative to the market is performed. This qualitative assessment considers the factors below.
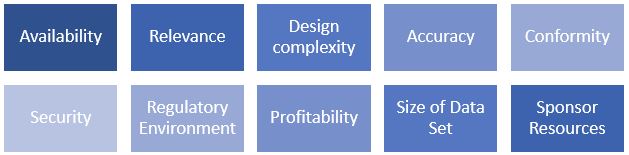
The pricing structure for data varies widely and can be structured on a per record or per study basis. Other times, a database fee or licensing fee is charged on an annual basis for access to a longitudinal data set that is continually updated with new data points. We have also observed transactions whereby the consideration paid is in the form of an equity stake in artificial intelligence companies for use of existing and future health data. As market comparisons may not always be available, it is also appropriate to consider a Cost Approach when valuing data.
The Cost Approach provides an indication of the market value of an asset based on the principle of substitution. The principle states that a potential licensee will pay no more for an asset than the cost to obtain, by purchasing or constructing, a substitute asset of equal utility. In applying the Cost Approach, we consider the costs incurred in the development, operation, maintenance and modification of a database when assessing the value of a data set.
When Data Value Matters
Often times the sale or purchase of data must be transacted at fair market value. Below are some examples of when the fair market value of data is important:
- Healthcare transactions implicating the Stark Law/Anti-Kickback Statute
- A pharmaceutical or medical device company may purchase or license de-identified patient data from a specialty pharmacy or healthcare provider in order to understand prescribing patterns, long-term efficacy trends, patient demographics and potential market opportunities. The overpayment for de-identified patient data may be construed as disguised rebates or reverse kickbacks.
- Over 35 states have enacted their own particular laws that govern self-referrals and fee splitting, which in certain cases can be stricter that Federal laws.
- California Business and Professions Code Section 650 governs fee-splitting and kickback practices for healthcare practitioners in California[9].
- Private Inurement
- Memorial Sloan Kettering (“MSK”) is a charitable organization that licensed de-identified data to Paige.AI, a for-profit start-up artificial intelligence company[10]. As various investors in Paige.AI are ‘insiders’ at MSK (e.g., board members or department chairs), it is important that assets are not provided for less than fair market value.
- Strategic transactions
- A health system may purchase a telehealth company that has collected patient data through provision of remote patient monitoring. As one of the assets included in the transaction is de-identified patient data, it may be important for the acquirer to understand the FMV of the de-identified data.
Summary
While companies that have developed propriety data may simply be looking to license its health data to various third parties, other times there are fair market value implications related to the sale of de-identified patient data. In either of these situations, HAI is able to help determine the fair market value of the health data being transacted.
10.1377/hlthaff.27.3.759